[学习]C++性能分析实战
小 Tips
⚠需要更加高级,细致到CPU时钟、缓存一致性、缓存命中率和分支预测准确率的估计考虑使用隔壁的 perf 工具 ⚠gprof只能检查工作在用户态的代码,如printf等内核态的代码无法剖析, ⚠在那之前回顾 c++ 程序,函数的声明与函数的定义二者之间区别。 ✔非常赞赏使用 git 代码管理工具。 ✔非常赞同合作写代码时规定一个统一的风格规范。
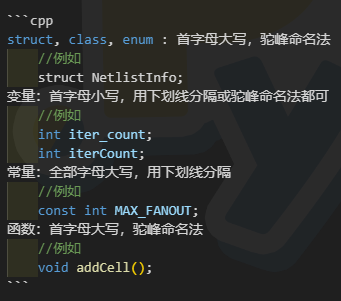
✔推荐使用 Makefile 自动构建工具。熟知 cmake 工具使用的话,更好。 ✔给自己的代码库写一个 README.md 文件
STL 库的使用
📌如果编译器能正确优化这两部分的调用,也许差别不大。但在一个逻辑复杂的类调用里面,指望编译器优化是不可行的。 ⚠STL库相比指针实现真的慢非常多,因此在考虑 return std::vector std::map std::list 等等 STL 库之前一定要想清楚,真的非 return 这些不可?能不能传一个 vector map list 的引用或者一个指针?
1 | |
以上两种实现方式都可以获得一个操作后的 map
数据类型,唯一不同的是返回形式,第一种返回 stl 容器本身,第二种 stl
容器则以引用参数的形式传递。 二者最大的差异在于返回 stl
容器,会引入额外的 stl
容器的创建和销毁过程。而引用形式则可以避免这部分额外开销。当我以n=10的规模大量调用超过1千万次时,二者的性能有显著的差别。
1
2
3
4wa@HAS-T640:~/EDA8$ g++ b.cpp -o b
wa@HAS-T640:~/EDA8$ ./b
copyReturn: 35808ms
refReturn: 30298ms
同样的代码,把 map 换成 unordered_map 再次执行会得到以下结果。
1
2
3
4wa@HAS-T640:~/EDA8$ g++ b.cpp -o b
wa@HAS-T640:~/EDA8$ ./b
copyReturn: 42165ms
refReturn: 40512ms
正确使用 Inline 修饰
⚠需要大量调用的函数,例如仅仅 return 一个 class 内 private 值,也许应该尝试把 private 移动到 public 类型中,减少函数调用带来的性能开销。这便是 inline 修饰的意义。 ⚠加上 inline 关键字并开启 -O2 以上的优化级别,剩下的靠编译器。当然,要熟知 inline 关键字修饰的本质,写的 inline 关键字才能被真正识别。
Inline 关键字的本质是把函数定义插入到调用的地方,从而减少调用栈的开销。 以下举例来自某小队的代码实现。 代码中有一处计算用的特别多,计算两个点的曼哈顿距离,他们在 *.hpp 文件声明了这个函数。
1 | |
然后在对应的*.cpp文件实现这个函数。 1
2
3double getManhatonDistance(Position &u, Position &v) {
return abs(u.x - v.x) + abs(u.y - v.y);
}-O2级别的优化,理论上编译器识别这种inline的函数十分轻松,是不应该出现不优化的情况的。事实不然,测试实际,这个函数被调用42亿次,且都是正常函数调用栈。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
38.56 5.19 5.19 94 0.06 0.09 KMeans::assignLabels(std::vector<Position, std::allocator<Position> >&)
37.75 10.27 5.08 4218676471 0.00 0.00 getManhatonDistance(Position&, Position&)
18.28 12.73 2.46 4 0.62 0.97 KMeans::initCenters(std::vector<Position, std::allocator<Position> >&)
5.20 13.43 0.70 146159 0.00 0.00 frame_dummy
0.07 13.44 0.01 49680 0.00 0.00 ClockTreeNode::setFather(ClockTreeNode&)
0.07 13.45 0.01 5885 0.00 0.00 void std::vector<int, std::allocator<int> >::_M_realloc_insert<int const&>(__gnu_cxx::__normal_iterator<int*, std::vector<int, std::allocator<int> > >, int const&)
0.07 13.46 0.01 51 0.00 0.00 void std::vector<ClockTreeNode, std::allocator<ClockTreeNode> >::_M_realloc_insert<ClockTreeNode const&>(__gnu_cxx::__normal_iterator<ClockTreeNode*, std::vector<ClockTreeNode, std::allocator<ClockTreeNode> > >, ClockTreeNode const&)
0.00 13.46 0.00 101270 0.00 0.00 std::vector<Position, std::allocator<Position> >::_M_default_append(unsigned long)
0.00 13.46 0.00 49681 0.00 0.00 ClockTreeNode::printComponent(std::ostream&)
0.00 13.46 0.00 49680 0.00 0.00 ClockTreeNode::addChild(ClockTreeNode&)
0.00 13.46 0.00 988 0.00 0.00 ClockTreeNode::printNet(std::ostream&)
0.00 13.46 0.00 94 0.00 0.00 KMeans::updateNewCenters(std::vector<Position, std::allocator<Position> >&)
0.00 13.46 0.00 34 0.00 0.00 void std::vector<Position, std::allocator<Position> >::_M_realloc_insert<Position const&>(__gnu_cxx::__normal_iterator<Position*, std::vector<Position, std::allocator<Position> > >, Position const&)
0.00 13.46 0.00 6 0.00 0.00 UnionFind::getRoot(int)
0.00 13.46 0.00 5 0.00 0.00 std::vector<int, std::allocator<int> >::_M_default_append(unsigned long)
0.00 13.46 0.00 4 0.00 0.00 KMeans::deleteEmpty(std::vector<Position, std::allocator<Position> >&)
0.00 13.46 0.00 4 0.00 3.18 KMeans::fit(std::vector<ClockTreeNode, std::allocator<ClockTreeNode> >&)
0.00 13.46 0.00 2 0.00 0.00 std::vector<double, std::allocator<double> >::_M_default_append(unsigned long)
0.00 13.46 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z16parseProblemFileRKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEER11NetlistInfoRSt6vectorI13ClockTreeNodeSaISA_EE
0.00 13.46 0.00 1 0.00 0.00 _GLOBAL__sub_I__ZN6KMeans3fitERSt6vectorI13ClockTreeNodeSaIS1_EE
0.00 13.46 0.00 1 0.00 0.00 _GLOBAL__sub_I__ZN7safeNum3addEi
0.00 13.46 0.00 1 0.00 0.00 _GLOBAL__sub_I_kmeans1
2
3
4
5
6
7double getManhatonDistance(Position &u, Position &v); // 在 hpp 文件强行修改 inline
// 错误方法,注意这只是函数的声明,没有解决错误
inline double getManhatonDistance(Position &u, Position &v); // 会在其他 cpp 文件引起函数未定义的错误
// 正确方法是,修改成函数的定义,加上函数实现部分
inline double getManhatonDistance(Position &u, Position &v) {
return abs(u.x - v.x) + abs(u.y - v.y);
} // 然后在 cpp 中删去这部分实现代码,防止重定义错误
判断条件 tips
⚠尽量不要在判断条件中引入过于复杂的函数,执行时间很长的函数。 ⚠非写不可,需要按照各个函数执行用时从低到高的顺序从左往右写。如果某个条件判断 false 概率更高,则可以适当提前。
1 | |
makefile 自动构建工具的使用
📌建议使用自动化构建工具。 ⚠但是本比赛不推荐 cmake 工具,因为 cmake 的语法复杂,上手难度较高,日后管理大型项目构建时,再学也来得及。
在当前文件夹内创建Makefile文件,并以扁平式分布所有的源代码文件。
例如,程序需要global.cpp util.cpp
rsmt.cpp arch.cpp lib.cpp
object.cpp netlist.cpp main.cpp
algorithm.cpp共计 9 个源代码文件编译得到,写出以下的
makefile 内容。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17SRC = global.cpp util.cpp rsmt.cpp arch.cpp lib.cpp object.cpp netlist.cpp main.cpp algorithm.cpp
OBJ = $(SRC:.cpp=.o)
CC = g++
CFLAGS = -Wall -Wextra -std=c++11
CFLAGS += -fopenmp -g
all: checker
checker: $(OBJ)
$(CC) $(CFLAGS) -o main $(OBJ)
%.o: %.cpp
$(CC) $(CFLAGS) -c $< -o $@
clean:
rm -f main $(OBJ)1
2
3
4
5
6SRC = global.cpp util.cpp rsmt.cpp arch.cpp lib.cpp object.cpp netlist.cpp main.cpp algorithm.cpp // 编译源文件
OBJ = $(SRC:.cpp=.o) // 指定编译对象
CC = g++ // 指定编译器
CFLAGS = -Wall -Wextra -std=c++11 // 规定基本编译参数
CFLAGS += -fopenmp -g // 附加参数make checker命令时会发生什么。
1
2
3
4
5checker: $(OBJ) // 冒号后表示编译 checker 依赖,$ 符号表示以变量形式看待
$(CC) $(CFLAGS) -o main $(OBJ) // 翻译过来这里写的是 g++ -Wall -Wextra -std=c++11 -fopenmp -g -o main [*.o]
%.o: %.cpp // 实际上 $(OBJ) 恰好是 global.o util.o 等等的缩写,会匹配到这个规则
$(CC) $(CFLAGS) -c $< -o $@make clean实际上执行的是rm -f main global.o util.o ...
1
2clean:
rm -f main $(OBJ)
一、Gprof工具的使用
⚠工具主要用于分析函数调用,不要引入多线程,尤其是锁机制会误导热点分析。 ⚠建议开启编译器 -O2 级别的优化。
gprof 通常作为 GNU Binutils 的一部分,在大多是 Linux 发行版中已经集成。 gprof 是 GNU 项目中性能分析工具,用于分析每个 C、C++ 函数调用和函数调用时间。它通过测量程序执行过程中的函数调用频率和运行时间来帮助定位程序热点和热点函数。从而定位可能的性能瓶颈。
1、使用步骤
a、编译前
在使用 gcc 编译 C++ 程序代码时,在编译参数内加入 -pg
告诉编译器引入 gprof 代码,例如: 1
g++ -g -pg -o main main.cppgprof 性能分析所需的全部代码。
🔥正式提交程序记得删除编译参数 -pg
,性能分析所需代码本身会拖慢程序。
b、像平常一样运行程序
1 | |
正常运行程序后,会在本地目录下生成一个 gmon.out
的文件,文件内记录程序运行的所有信息。 ### c、可视化报告 调用
gprof 工具可视化 gmon.out 文件,执行一下命令:
1
gprof main gmon.out > analysis.txtanalysis.txt
的文本文件,里面记载程序运行的函数调用信息和数据信息。
2、如何分析
a、第一部分
初次打开 analysis.txt 文件,看到内容如下: 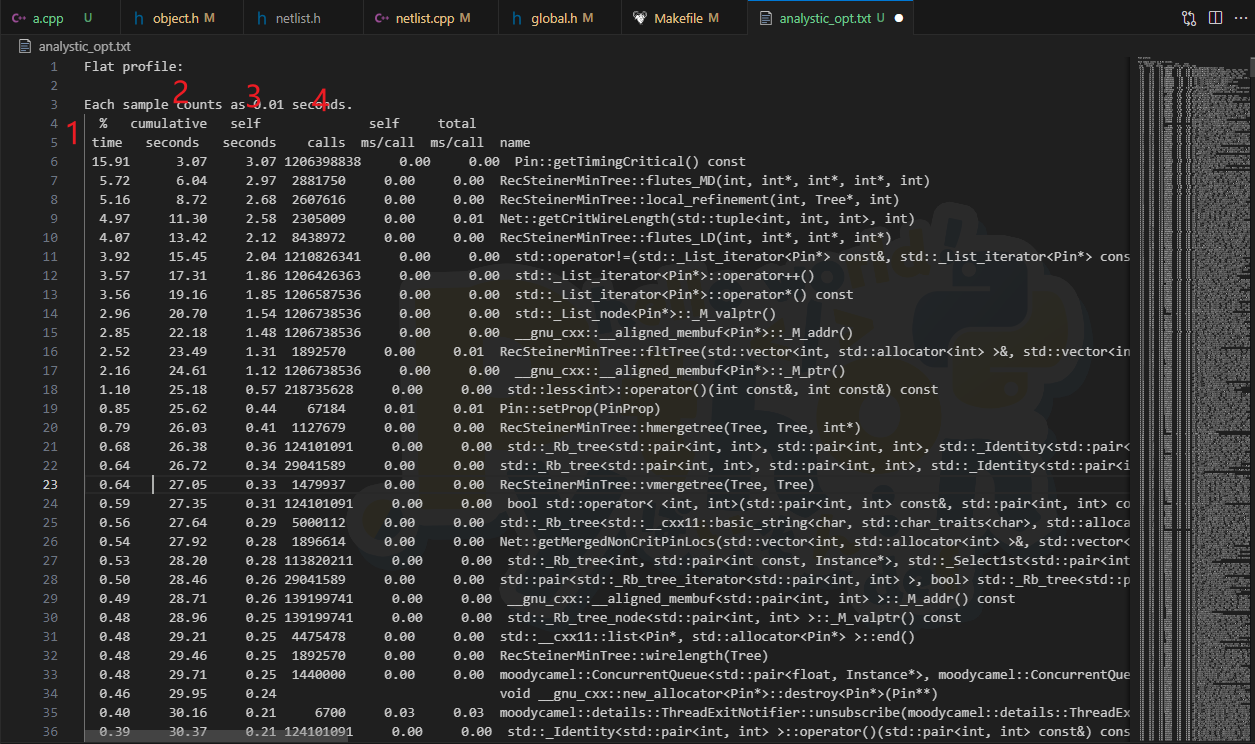
一列一列来观察: 1. 第一列说明当前函数运行时间占程序总运行时间的百分比。这里一眼看到 Pin::getTimingCritical() 调用了 12 亿次,占用时间高达 16% ,优化的第一步必然是它。 2. 第二列是累计运行时间,一般不关注。 3. 第三列是函数运行时间,可以看到这个函数 Pin::getTimingCritical 总共的运行时间为 3 秒。 4. 第四列说明函数被调用次数。有时候一个函数运行缓慢不是函数本身问题,是被 call 了太多次。因此函数本身不是优化对象应该重点关照其调用次数。
b、第二部分
看完第一部分,可以基本了解程序中热点和热点产生的原因,但是无法告诉你如何去优化,比如知道
Pin::getTimingCritical
函数被调用很多次,但是不知道在哪些地方被调用了。
这时候继续向下查看,在大约 1000~5000
行左右的位置,观察到如下所示结果:
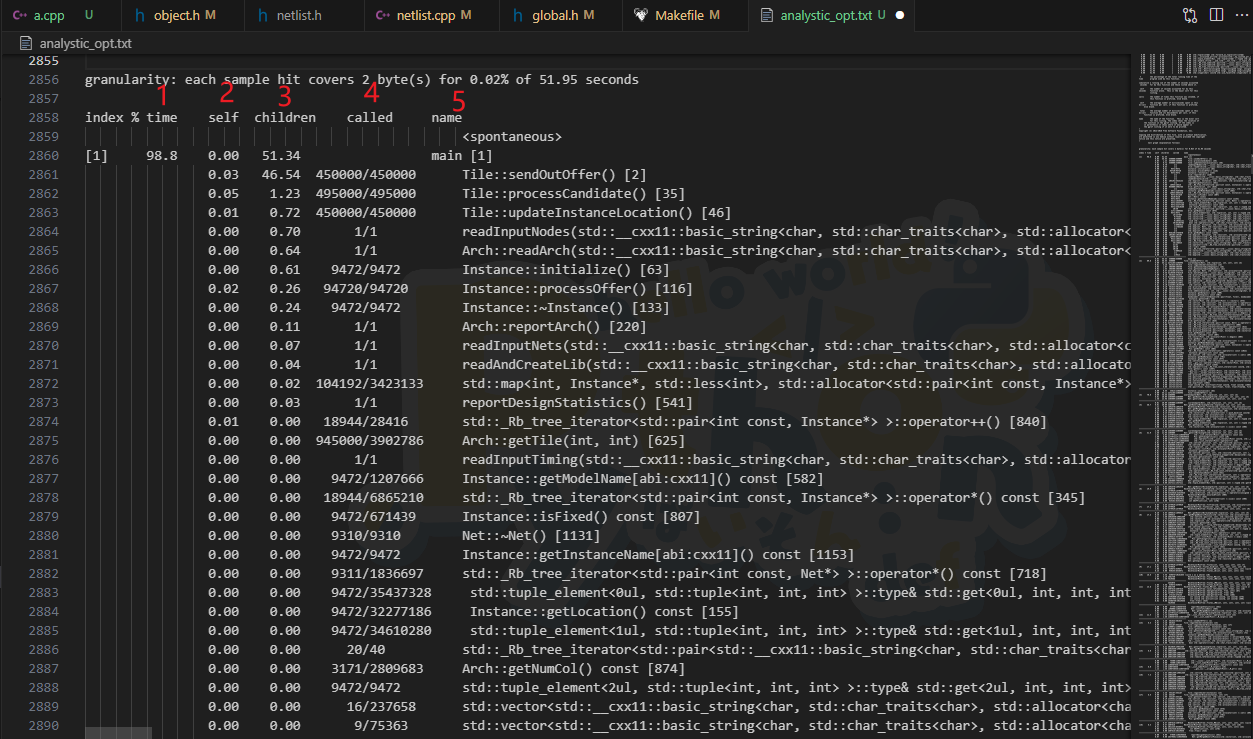
- 第一列告诉你,当前函数运行时间占总时间的百分比,打头的一定是 main 函数。
- 第二列,函数自身用时,不包括函数内部调用的用时,例如 Tile::sendOutOffer 函数占用了 51 秒运行时间的 46 秒,但是自身运行仅仅 0.03 秒,因此 Tile::sendOutOffer 自身不是性能瓶颈,问题在这个函数内部调用上。
- 第三列,函数加上内部调用总运行时间。
- 第四列,左边是在 main 中该函数调用次数,右边是总调用次数。用于定位调用次数的热点。
- 第五列,函数名称,附带的方括号是 index 列的位置。
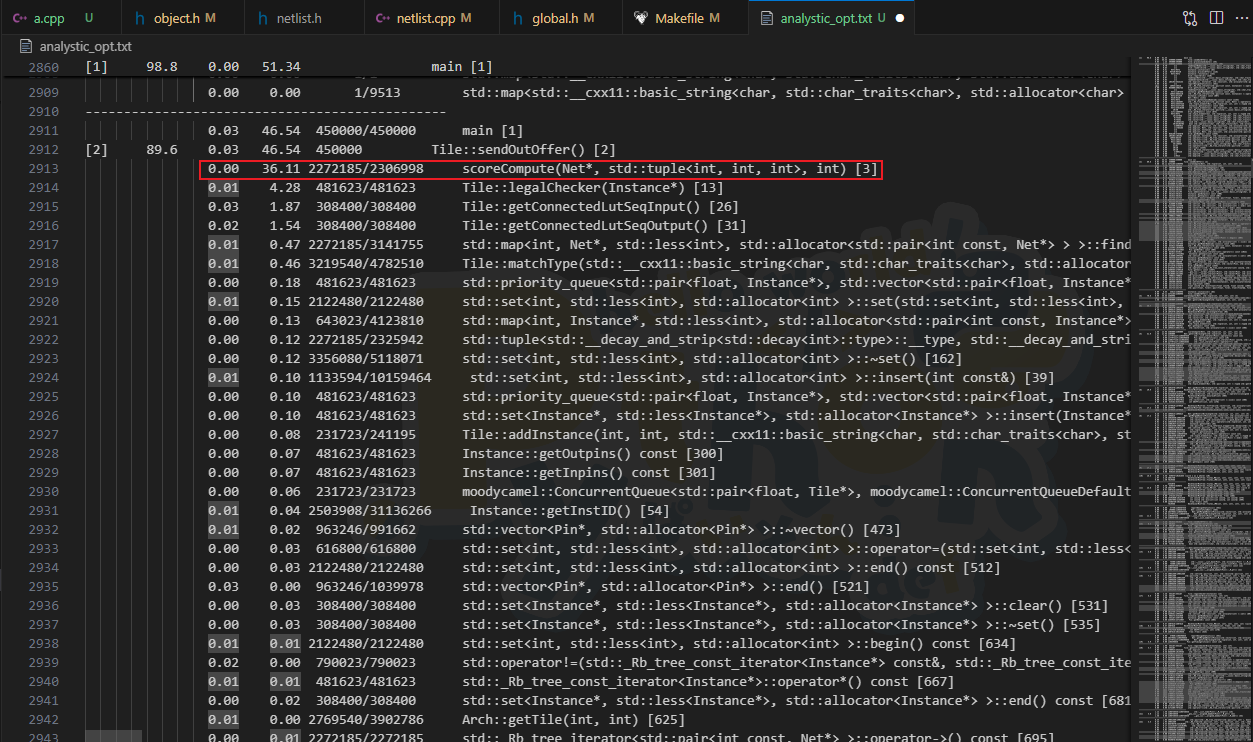
继续往下,查看 Tile::sendOutOffer
函数的运行时间占比,发现 scorecompute 是大头。并且
Tile::sendOutOffer 贡献了 scoreCompute 超过
99% 的调用次数。 基本确定方针,优化 scoreCompute
的运行时间,减少 Tile::sendOutOffer 对
scoreCompute 的非必要调用。
3、多线程
这个方法也能看到多线程的程序运行时间,但是不建议。里面统计的函数调用次数不可信,子函数调用时间基本不可信。但是在锁机制等相关信息的探查上可以看出一些端倪。 比如说:如果程序使用过多锁机制,锁同步是程序缓慢的重要原因,那么可以看到 lock 的加锁函数调用占用了大量时间。
二、valgrind 多线程性能分析
想到吧,内存检测工具也提供了对于多线程锁竞争的性能分析。这里尝试使用其中线程分析工具来定位多线程程序运行缓慢问题。 本质上是使用 ValGrind 的函数调用分析工具实现的。
一些说明 1. 相比 gprof 在编译程序时不需要额外参数,但是推荐加上
-g 调试参数。 2. 这个工具不建议开启任何的代码优化选项,如
-O2 、 -O3 等等,防止定位到错误的代码行。 3.
原始输出十分难以阅读,建议使用部分开源的数据阅读器(如 kcachegrind)进行可视化性能分析。
1、使用步骤
1 | |
如果是多线程,那么需要额外加上一行参数,valgrind
工具会为每个线程单独生成一个记录文件 callgrind.out.xxx
(其中的xxx代表进程号),方便之后探查。 1
valgrind --tool=callgrind -separate-threads=yes ./a.outcallgrind.out.xxx
和 callgrind.out.xxx-01 …… 后面的数字代表不同的线程。
2、如何分析
找到上一步生成的文件 callgrind.out.xxx
,如果有可视化分析工具,可以使用工具打开文件。这里将要说明如果没有下载工具如何去分析程序。
a、没有可视化工具时
利用自带的 callgrind_annotate 工具,然后把输出写到
run.log 上并打开。
1 | |
打开文件发现如下: 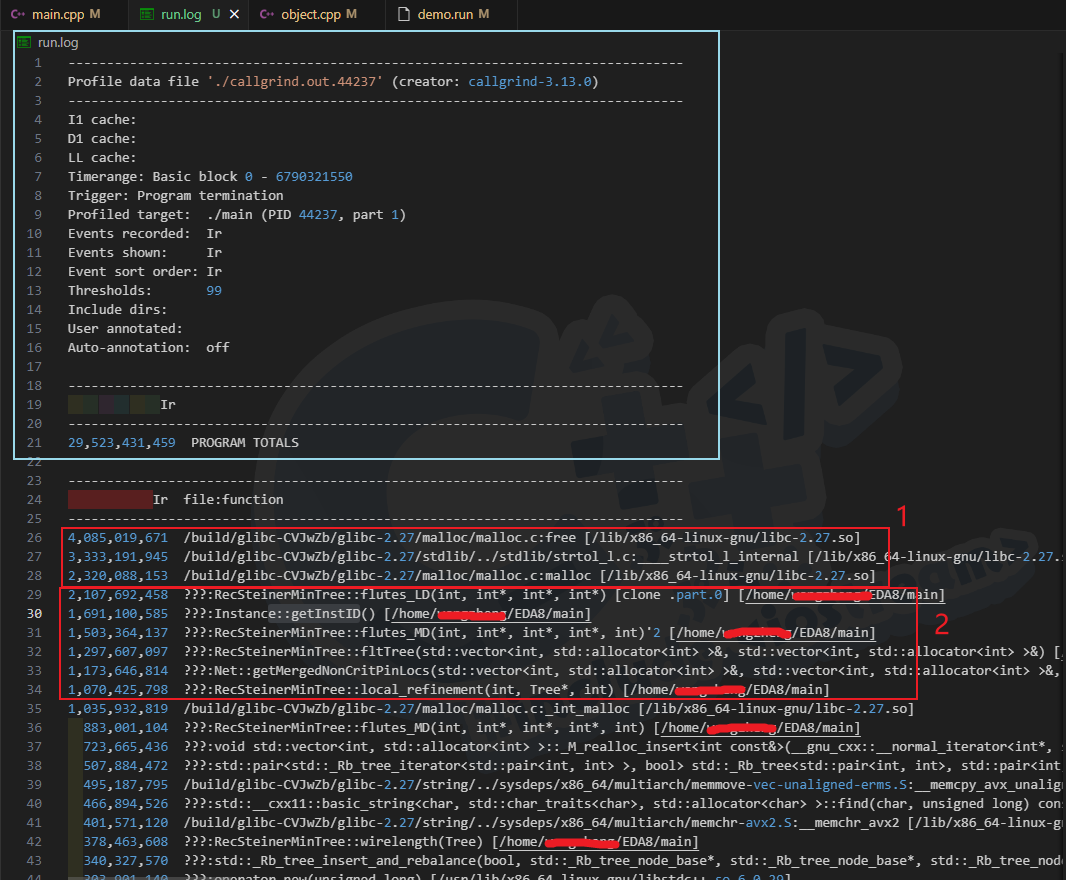
- 忽略淡蓝色框内容,那只是一些基本信息。
- 红色框1,函数头开始部分是一个绝对路径,说明是标准库的调用,这里举例是 malloc 和 free 标准库。
- 红色框2,函数头是
???是本地代码,编译时没有绝对路径,可以以此区分标准库和自己实现的部分。 但是,这个程序的功能也就到此为止了,只能看到哪些函数的调用次数最多,完全看不见各个函数的执行时间与调用栈的分布情况。
b、有可视化工具时
这里因为打不开服务器的远程桌面了,网上找了一个类似的图,效果差不多。

3、番外
valgraind工具还可以检测锁竞争和死锁情况。使用
helgrind工具可以检测锁竞争情况。
三、Vtune多线程分析工具
仅Intel的CPU可用,具体可以参考intel的官网手册。
因为我是 AMD 铁粉,没有 intel 的 U 就没有介绍。
将来用上了再考虑学习。